MedGemma
综合介绍
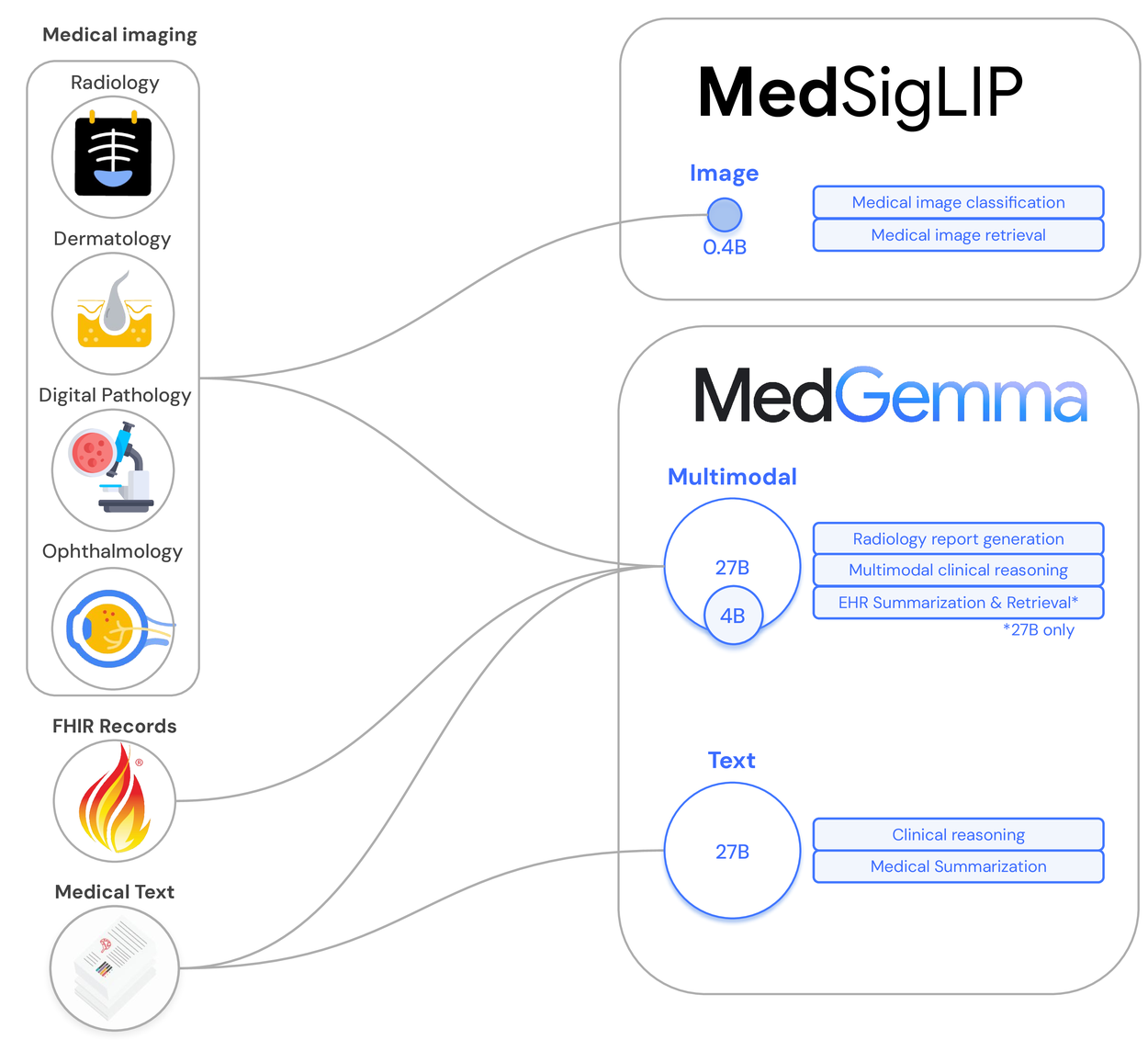
MedGemma是谷歌发布的一系列专为医疗领域设计的开源人工智能模型。 这些模型基于先进的Gemma 3架构,并针对医疗数据进行了特别优化,能够同时理解和处理复杂的医疗文本与医学影像,例如病历、研究论文和X光片。 MedGemma系列包括不同规模和功能的版本,如4B(40亿参数)和27B(270亿参数)的多模态模型,以及一个专门处理文本的27B模型,可以满足不同的应用需求。 谷歌将MedGemma作为研究模型发布,旨在为医疗AI开发者和研究人员提供一个强大的基础工具,帮助他们加速构建能够保护数据隐私、可本地部署和定制化的医疗AI应用。 虽然模型在多个医学知识测评中表现出色,但官方强调,它目前并非临床级产品,在实际应用中需要经过针对性的微调、验证和专业人员的监督。
功能列表
- 多模态数据处理: 能够同时接收文本和图像作为输入,并生成文本输出,支持对病历和对应医学影像的综合分析。
- 医学影像解读: 可用于生成医学影像的初步报告,或用自然语言回答关于影像内容的问题。
- 医学知识问答: 经过大量医学文本训练,在MedQA等标准医疗知识基准测试中取得了很高的准确率。
- 文本生成: 27B的纯文本模型专用于处理和生成高质量的医疗相关文本内容。
- 零样本图像分类: 包含的MedSigLIP模型专为医学图像和文本的编码设计,可用于高效的图像分类任务。
- 本地化部署: 作为开源模型,用户可以将其部署在本地服务器上,确保对敏感医疗数据的完全控制和隐私安全。
- 高度可定制: 开发者可以根据具体的医疗任务对模型进行微调,以提升在特定场景下的性能和准确性。
- 代理系统集成: 可以作为一个核心工具集成到更复杂的AI代理系统中,与其他工具(如网络搜索、电子病历系统)协同工作。
使用帮助
MedGemma系列模型已在Hugging Face上开源,开发者可以借助transformers等主流Python库方便地进行调用和集成。 下面将详细介绍如何配置环境及使用不同版本的MedGemma模型。
1. 环境准备
首先,你需要安装Python并配置好必要的库,主要是transformers、torch和Pillow(用于图像处理)。
pip install transformers torch pillow
2. 如何使用MedGemma模型
MedGemma主要分为纯文本模型和图文多模态模型,不同模型的使用方式略有差异。
使用 medgemma-27b-text-it(纯文本指令微调模型)
这个模型专门用于处理医疗相关的文本任务,如回答医学问题、总结病历等。
操作流程:
- 加载模型和分词器: 从Hugging Face加载
google/medgemma-27b-text-it模型及对应的分词器。 - 准备输入: 将你的问题或需要处理的文本内容整理成指令格式。
- 生成回答: 将准备好的输入传递给模型,并解码输出结果。
示例代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 指定模型ID
model_id = "google/medgemma-27b-text-it"
# 设置设备,优先使用GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
# 准备输入文本
prompt = "请解释一下什么是“高血压”,以及它的主要风险因素有哪些?"
# 使用分词器对输入进行编码
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 生成输出
outputs = model.generate(**inputs, max_length=500)
# 将输出解码为人类可读的文本
response_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response_text)
使用 medgemma-27b-it(图文多模态指令微调模型)
这个强大的多模态模型可以同时分析一张图片和相关的文字问题,并生成回答。非常适合用于解读医学影像。
操作流程:
- 加载模型和处理器: 多模态模型需要一个统一的处理器来同时处理文本和图像。
- 准备输入: 需要一张本地图片和一个与之相关的文本问题。
- 处理并生成回答: 使用处理器准备输入,然后由模型生成回答。
示例代码:
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
# 指定模型ID
model_id = "google/medgemma-27b-it"
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载处理器和模型
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForVision2Seq.from_pretrained(model_id).to(device)
# 加载本地的医学影像图片
# 假设你有一张名为 'chest_xray.jpg' 的胸部X光片
try:
image = Image.open('chest_xray.jpg').convert("RGB")
except FileNotFoundError:
print("错误:请确保名为 'chest_xray.jpg' 的图片文件在当前目录下。")
# 创建一个空白图片作为备用,以使代码可以继续执行
image = Image.new('RGB', (224, 224), color = 'grey')
# 准备文本提示
prompt = "根据这张X光片,请描述肺部是否存在异常?"
# 使用处理器准备模型输入
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device)
# 生成输出
generated_ids = model.generate(**inputs, max_length=512)
# 解码生成的文本
response_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response_text)
注意: 使用多模态模型时,确保你的环境中安装了Pillow库。提供的图片路径chest_xray.jpg需要换成你自己的实际图片路径。
3. 模型选择建议
- 如果你的任务只涉及文本分析,如处理电子健康记录、医学文献综述或知识问答,请选择
medgemma-27b-text-it,因为它更专注,效率更高。 - 如果你的任务需要结合视觉信息进行判断,例如放射影像报告生成、皮肤病变识别辅助等,请使用
medgemma-4b-it或medgemma-27b-it等多模态版本。 - 对于刚入门的开发者或计算资源有限的情况,可以从
medgemma-4b系列开始尝试,它的参数量更小,对硬件的要求也更低。
应用场景
- 医学研究辅助研究人员可以利用MedGemma快速分析和总结大量的医学文献、临床试验报告和病人数据,从而加速科学发现的进程。例如,模型可以识别不同研究中的关联性,或对复杂的生物医学概念生成通俗易懂的解释。
- 临床决策支持在医生的监督下,MedGemma可以作为一个辅助工具,提供对病情的第二意见。例如,通过分析患者的电子病历和最新的医学影像,模型可以提示潜在的诊断方向或推荐相关的诊疗指南。
- 医疗健康应用开发开发者可以基于MedGemma创建面向消费者的健康应用,如智能问诊、症状自查或用药提醒工具。模型的本地化部署特性确保了用户敏感健康数据的隐私安全。
- 医学教育与培训MedGemma可以用于构建模拟诊断系统,帮助医学生在虚拟环境中练习。学生可以向系统提交“病例”(文本描述+影像),并获得模型的分析与反馈,以此提升临床思维能力。
QA
- MedGemma是免费的吗?是的,MedGemma是谷歌发布的开源模型,开发者和研究人员可以免费下载和使用,但需要遵守其相关的开源许可协议。
- 我可以直接将MedGemma用于临床诊断吗?不可以。谷歌明确指出,MedGemma是一个研究模型,并非经过认证的临床级产品。 任何基于它开发的医疗应用在投入实际使用前,都必须经过严格的临床验证和监管审批,并且始终需要在专业医生的监督下使用。
- 运行MedGemma需要什么样的硬件?这取决于模型的版本。4B(40亿参数)的版本对硬件要求较低,而27B(270亿参数)的版本则需要更强大的计算资源。不过,谷歌在设计时已进行了优化,使得在单个专业级GPU上进行微调和推理成为可能,这让它比许多其他大型模型更加易于部署。
- MedGemma支持中文吗?模型的主要训练数据是英文的医疗文本和资料。虽然它可能具备一定的基础多语言能力,但在处理中文医疗信息时的准确性和可靠性未经充分验证,可能需要针对中文数据进行专门的微调才能达到理想效果。